Ein Drama in 7 Akten. Unser zentraler Datenspeicher hält uns auf Trab.
Inhaltsverzeichnis
Ende November 2017 erreichten wir einen Meilenstein: Wir haben unseren zentralen Datenspeicher und damit alle Websites unserer Kunden auf superschnelle SSD umgestellt. Die Benchmarks waren fantastisch. Die Kunden überglücklich. Wir auch.
Kurz erklärt: Was ist ein zentraler Datenspeicher?
Ein zentraler Datenspeicher (im Fachjargon «Storage») ist bildlich gesprochen eine riesige grosse externe Festplatte, die mit unseren Servern verbunden ist. Auf dieser Festplatte können unsere Server Daten speichern.
Das bringt zwei entscheidende Vorteile:
- Ist eine lokale Festplatte in einem Server voll, kann diese nicht einfach erweitert werden. Auf einem zentralen Datenspeicher hingegen können jederzeit weitere Festplatten hinzugefügt und der Platz so vergrössert werden.
- Fällt ein Server aus, kann der Storage an ein Ersatzsystem angeschlossen werden. Alle gespeicherten Daten sind dann auf dem Ersatzsystem sofort wieder verfügbar.
Kurz erklärt: Was ist SSD?
SSDs bzw. Solid-State-Drives sind Festplatten, die (im Gegensatz zu ihren Vorgängern, den HDDs bzw. Hard-Disk-Drives) komplett ohne mechanische Teile auskommen. Eine SSD ist dadurch enorm viel schneller als eine HDD (bis zu 1000-mal schnellere Zugriffszeiten). Und das macht auch den Zugriff auf Ihre Website-Daten schneller.
Kurz nach dem Jahreswechsel standen dann ein paar Updates unseres Datenspeichers auf dem Programm. Guter Dinge haben wir also losgelegt. Doch da tauchte wie aus dem Nichts ein Problem auf: Die Performance unseres Datenspeichers war plötzlich im Keller.
Erste Kunden haben sich bei uns gemeldet. Wir waren ahnungslos. Und ziemlich frustriert.
Vor wenigen Tagen (bzw. Nächten) dann die grosse Erlösung: Wir haben das Problem gefunden. Die volle Performance ist zurück. Entsprechend gross die Erleichterung. Doch was war das Problem?
In diesem Blogpost nehmen wir Sie mit auf eine Reise hinter die Kulissen und in die Tiefen eines zentralen Datenspeichers. Und möglicherweise hilft dieser Beitrag irgendwann und irgendwo einem anderen verzweifelten Ceph-Administrator.

Die Ausgangslage: Ein Update steht an
Ein zentraler Datenspeicher besteht aus zwei Komponenten:
- Der Hardware: Also aus den eigentlichen Festplatten. Diese Festplatten sind in Server eingebaut, was bei uns dann ungefähr so aussieht:

- Der Software, welche die Hardware steuert. In unserem Fall ist das Ceph.
Für Ceph werden regelmässig neue Versionen veröffentlicht, welche Fehler beheben und neue Funktionen bringen. So gehört es also zu den Routineaufgaben eines Ceph-Administators, alle paar Monate ein solches Update einzuspielen.
Am 2. Januar 2018 haben wir mit den vorbereitenden Arbeiten begonnen:
- Wir haben das Betriebssystem aller Ceph-Nodes von RHEL 7.3 auf RHEL 7.4 aktualisiert – damit einher gehen viele Treiber-Updates, ein neuer Kernel etc.
Kurz erklärt: Was ist RHEL, ein Treiber oder ein Kernel?
- RHEL steht für Red Hat Enterprise Linux und ist ein Betriebssystem, also die «Basissoftware» auf einem Computer, analog Windows, Mac OS, Android usw.
- Ein Treiber beschreibt dem Betriebssystem angeschlossene Hardware, damit das Betriebssystem mit dieser interagieren kann.
- Ein Kernel ist das Herz eines Betriebssystems, welches z.B. festgelegt, wie Prozesse oder Daten organisiert werden.
- Selbiges haben wir auf den sogenannten Hypervisors gemacht, also unseren Servern, die wiederum die (virtuellen) Kundenserver beherbergen.
Kurz erklärt: Was ist ein virtueller Server? Und ein Hypervisor?
- Ein virtueller Server schummelt. Er gibt sich nämlich als normaler Server aus, ist aber nur simuliert bzw. eben virtualisiert. Das darauf installierte Betriebssystem merkt davon nichts. Und warum macht man das? Man entkoppelt so das Betriebssystem von der eigentlichen Hardware und kann einen virtuellen Server im laufenden Betrieb auf ein Ersatzsystem verschieben. Unsere Kundenserver sind alle virtualisiert.
- Ein Hypervisor ist in diesem Kontext die eigentliche Hardware, auf welchem virtuelle Server liegen.
- Zeitgleich wurden die Sicherheitslücken Meltdown und Spectre bekannt und wir haben flottenweit Patches eingespielt.
Kurz erklärt: Was ist ein Patch?
Ein Patch ist ein kleines Software-Update, welches einen Fehler behebt. Das Wort Patch (aus dem engl. für Pflaster) hat seinen Ursprung übrigens aus der Zeit der Lochkarten, wo Löcher an falscher Stelle mit einem Pflaster geschlossen wurden.
- Während den Updates wurde uns ein Bug bekannt: Sind HDDs und SSDs in einem Server (in diesem Kontext auch Node genannt) gemischt, können Daten, die aus Gründen der Redundanz zwingend auf verschiedener Hardware abgelegt werden müssten, auf dem gleichen Node gespeichert werden. Fällt ein Node aus (z.B. bei einem Neustart nach einem Kernel-Update), schaltet Ceph die davon betroffenen Daten in den Nur-Lesen-Modus, weil die Konsistenz der Daten nicht mehr gewährleistet werden kann.
Unseren Kundenservern gefällt das natürlich gar nicht, wenn sie plötzlich nicht mehr Daten schreiben können. Die vorläufige Lösung für das Problem: Von drei Kopien auf vier Kopien erhöhen. So konnten wir sicherstellen, dass immer ausreichend Kopien aller Daten auf unterschiedlicher Hardware gespeichert ist.
Kurz erklärt: Was ist ein Node? Was ist Redundanz? Und wie funktioniert das mit den Kopien?
- Ein Node ist in diesem Kontext ein Server mit vielen eingebauten Festplatten, so wie oben abgebildet. Mehrere Nodes zusammen (sowie noch weiteren Server zur Steuerung) ergeben dann den gesamten zentralen Datenspeicher. Wird der Platz knapp, kann der zentrale Datenspeicher einfach mit weiteren Nodes erweitert werden.
- Redundanz (hier
besserunterhaltsamer erklärt) beschreibt eine Methode, die Ausfallsicherheit zu erhöhen, in dem einzelne Komponenten mindestens doppelt vorhanden sind. - Ein zentraler Datenspeicher ist so ausgelegt, dass der Ausfall einzelner Teile (also z.B. einer einzelnen Festplatte oder auch einem ganzen Node) den Betrieb nicht beeinträchtigt und vor allem keine Daten verloren gehen. So speichert Ceph beispielsweise alle Daten mehrfach. In unserem Fall werden alle Daten drei Mal gespeichert, d.h. jede Datei ist auf drei unterschiedlichen Festplatten abgelegt. Fällt eine Festplatte aus, gibt es immer noch zwei Kopien der sich darauf befindlichen Daten. Fällt eine weitere Festplatte aus, verändert Ceph die letzte übrig gebliebene Kopie nicht mehr, bis wieder mindestens zwei Kopien vorhanden sind.
- Am 8. Januar dann haben wir mit dem eigentlichen Update der Ceph-Software begonnen. Das Update wird Stück für Stück ausgerollt und tangiert mehrere Stellen: Sowohl die Nodes wie auch die Kundenserver.
Und während all diesen Updates merken wir: Die Performance ist nicht mehr, wie sie sein soll.
Die Performance bricht ein. Was ist nun schuld?
Das Problem: Wir haben in der Vorbereitung mindestens fünf umfangreiche Änderungen in relativ kurzer Zeit vollzogen, was die Fehlersuche entsprechend schwierig gestaltete.
Mit vereinten Kräften, Beihilfe des Herstellers Red Hat und in unzähligen, zusätzlichen Nachtschichten haben wir uns akribisch vorgearbeitet. Dabei galt es nach dem Ausschlussverfahren herauszufinden, an welcher Stelle es genau klemmt. War es das Update des Betriebssystems? Die vierte Kopie? Das eigentliche Update von Ceph? Eine Konfigurationseinstellung in Ceph, die nicht (mehr) ideal ist?
Um jeweils einen Vergleich zu haben, führten wir vor und nach jeder gemachten Änderung Benchmarks durch. So auch am 30. Januar, als ein paar Änderungen an den Kerneleinstellungen vorgenommen wurden.
Kurz erklärt: Was ist ein Benchmark?
Ein Benchmark ist ein Vergleichsmassstab. In unserem Fall sind das wiederholt durchgeführte Geschwindigkeitstests, um den Einfluss einer gemachten Änderung feststellen zu können.
Zwei anschliessend ausgeführte Benchmarks im Abstand von ungefähr 30 Sekunden zeigten etwas Auffälliges: Die Ergebnisse lagen um Faktor 10 massiv weit auseinander.
Was schwankt hier so?
Das liess aufhorchen: Eine solche Diskrepanz innert so kurzer Zeit und bei etwa gleichzeitiger Auslastung war mehr als auffällig.
Ebenfalls interessant: Auf einigen Festplatten traten sogenannte Slow Requests auf – also Anfragen an die Festplatten, die über 30 Sekunden benötigen, um beantwortet zu werden. Das war jenseits von gut und böse und im Normalbetrieb absolut nicht erklärbar.
Ein Blick auf die Auslastung einer einzelnen Festplatte zeigte während des Auftreten der Slow Requests auch einen plötzlichen Sprung:
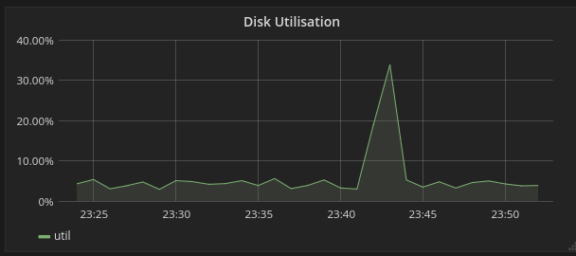
Das muss soweit nicht aussergewöhnlich sein: Es ist durchaus denkbar, dass eine Festplatte plötzlich mehr zu tun hat und etwas abarbeiten muss.
Nur: Die Festplatte hatte während dieser Zeit gar nicht mehr Arbeit zu erledigen:
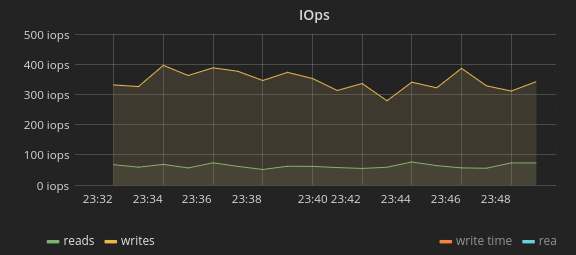
Die Anzahl Schreib- und Leseoperationen der Festplatte war in etwa konstant – ein plötzlicher Anstieg liess sich nirgends erkennen. Wie also konnte die Auslastung der Disk steigen, obwohl die anfallende Arbeit unverändert war?
In der Latenz, also der Reaktionszeit der Festplatte, war der Ausschlag dann wieder deutlich sichtbar:
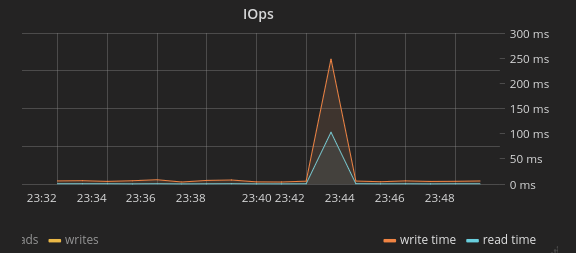
Ein erstes Muster lässt sich erkennen
Das Spiel ging weiter. Betrachtete man die Auslastung der Festplatte über einen grösseren Zeitraum, zeigte sich dieses Bild:
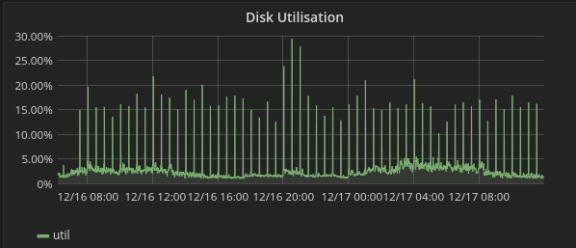
Was auffiel: Die Sprünge in der Auslastung erfolgten mit verdächtiger Regelmässigkeit. Und das auf allen Festplatten in einem Node gleichzeitig. Dann wurde es ganz verrückt: Die Sprünge in der Auslastung waren nicht nur auf den Festplatten zu sehen, die in den zentralen Datenspeicher integriert sind, sondern auch auf den Festplatten, auf welchen das Betriebssystem der Nodes abgelegt ist und welche mit dem Rest überhaupt nichts am Hut haben.
Die heisse Spur: Ceph ist unschuldig
An dieser Stelle wurde klar: Das Problem hat gar nicht direkt mit Ceph zu tun.
Ein Blick zurück verriet dann auch, ab wann diese seltsamen Lastspitzen auftreten:
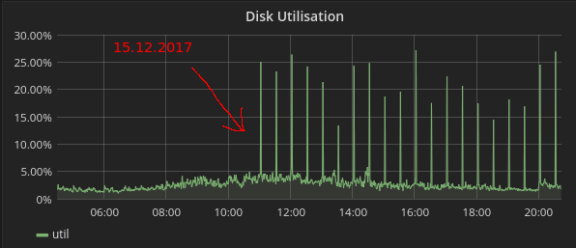
Am 15. Dezember. Da war doch unsere Weihnachtsfeier. Und ein Freitag. Auch ein Blick in unser internes Änderungsprotokoll zeigte nichts Verdächtiges:

Dann noch einen Blick in den internen Chat. Die brennende Frage: Was ist am 15. Dezember geschehen? Und da. In der Historie tauchte dieser Code-Schnipsel auf:

Die Puppen tanzen
Wir verwenden für das Management unserer Server das Tool Puppet. Alle 30 Minuten prüft Puppet die Konfiguration eines Servers und rollt ggf. Änderungen aus.
Für Puppet gibt es ein kleines Helferlein namens Facter, dass vor einem sogenannten Puppet-Run Informationen aufbereitet, die dann anschliessend von Puppet genutzt werden können. Solche Informationen können z.B. der verfügbare Arbeitsspeicher oder der verwendete Prozessor sein.
Und das Helferlein lässt sich auch erweitern. So ist es für uns z.B. wichtig, in einem Node die sogenannten Festplatten-IDs zu kennen. Damit können wir beispielsweise das Status-Lämpchen einer bestimmten Festplatte blinken lassen. Ist eine Festplatte defekt und muss ersetzt werden, lassen wir das Lämpchen blinken und der Mitarbeiter vor Ort hat eine zusätzliche Kontrolle, sicher die richtige Disk in den Fingern zu haben.
Jetzt taute es: Am 15. Dezember hatten wir das Tool «Facter» erweitert, damit es für uns fortan auch die Festplatten-IDs einsammelt. Eine winzige und unscheinbare Änderung, möchte man meinen.
Aber jetzt war der Fehler gefunden: Das Auslesen dieser Festplatten-Informationen führte dazu, dass alle Disks fehlerhafterweise für ungefähr 5 Sekunden nicht mehr reagieren. Das Auslesen geschieht über den RAID-Controller und, wie sich herausstellte, ist dieses Fehlverhalten ein Bug des RAID-Controllers. Ein Update der RAID-Controller-Firmware behebt das Problem.
Kurz erklärt: Was ist ein RAID-Controller?
Ein RAID-Controller ist ein Stück Hardware zwischen den eigentlichen Festplatten und dem restlichen Server. Dieser Controller kann dem Server gewisse Steuerungsaufgaben abnehmen und z.B. ein sogenanntes RAID erzeugen.
Was also ist genau passiert? Aktuell haben wir 34 Nodes in Betrieb. Wenn alle 30 Minuten Puppet bzw. Facter durchläuft, gerät durchschnittlich etwa alle 53 Sekunden ein einzelner Node für etwa 5 Sekunden ins Stocken.
Das gibt dann über den ganzen Datenspeicher gesehen (und Daten werden immer über den ganzen Datenspeicher verteilt) ca. 48 Sekunden Normalbetrieb, dann wieder 5 Sekunden stockender Betrieb und so weiter. Womit auch die unterschiedlichen Benchmark-Ergebnisse erklärt wären.
Die grosse Erlösung
Flink wurde also das Einsammeln der Disk-Informationen vorläufig abgeschaltet und voilà: Ein Blick auf einen Server zeigte Folgendes:
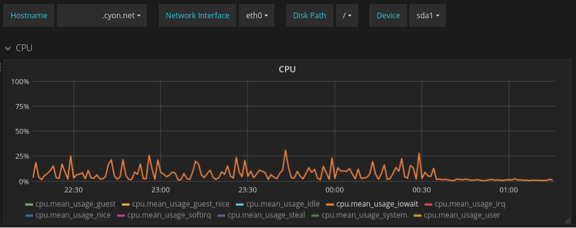
Die Kurve ist wieder, wie sie sein soll: flach.
Man sieht hier den sogenannten I/O-Wait, also die Zeit, welche ein Prozess auf dem Server auf Antwort des zentralen Datenspeichers warten muss.

Besonders gemein an der Sache war, dass die Performance-Einbussen schon seit dem 15. Dezember bestanden hatten, in diesen Tagen aber niemandem etwas aufgefallen ist. Schliesslich war ja auch Weihnachten und generell herrschte weniger Betrieb als sonst.
Somit haben wir die Quelle des Übels am völlig falschen Ort vermutet: In den Änderungen, die ab dem 2. Januar durchgeführt wurden.
Inzwischen sind wir enorm erleichtert und glücklich darüber, das Problem gefunden zu haben. Wir gehen mit einem grossen Zuwachs an Erfahrung aus dieser nervenaufreibenden Zeit hervor.
Und natürlich tut es uns leid, dass die Performance-Probleme gerade bei datenbankintensiven Operationen auch auf Kundenseite zu spüren waren. Dafür und für die entstandenen Unannehmlichkeiten möchten wir uns bei Ihnen in aller Form entschuldigen.
Bereit für den Wechsel?
Wechsle jetzt zu cyon für ein souveräneres und nachhaltigeres Internet.
Beteilige dich an der Diskussion
10 Kommentare

schade wäre es nur wenn man nichts daraus lernt. Müsste man die Benchmarks und weitere Tests (+automatische Analyse) nicht praktisch täglich durchführen? Oder den Prozess für System / Konfiguration Änderungen so erweitern das man dies a) gut nachvollziehbar sieht und b) spätestens danach ein Benchmark läuft?

Wir haben unser Monitoring erweitert und führen nun mehrmals pro Stunde Benchmarks aus. Die Resultate werden in Graphen aufgezeichnet, womit wir eine solche Situation nun deutlich einfacher erkennen können.

Leute!
Der grösste Teil ist ja immer noch Shared-Hosting! Ich behaupte es gibt in der Schweiz keinen besseren und transparenteren Service in der Schweiz.
Da werden einfach alle Karten offen gelegt. Kann sich manche Firma in Sachen Kommunikation eine Scheibe davon abschneiden!
Wenn ihr eine Siemens-Infrastruktur wollt, dann müsst ihr halt eure 5000.- pro Jahr für die Website ausgeben…
Ihr könnt wechseln so oft ihr wollt. Früher oder später passiert auch dem nächsten Hoster eine Panne.
Wenn ihr Gold wollt, dann müsst ihr auch in Gold zahlen…

Auch von mir vielen Dank für die offene Kommunikation.
Das generiert Vertrauen, dass einfach nichts verheimlicht wird.
Irren ist menschlich. Für einen grossen Fehler braucht man einen Computer.

Mir ist bewusst dass die Technik und Software immer komplizierte wird und es zu nicht geplanten Pannen und Ausfällen kommen kann, welche sicher nicht beabsichtigt sind.
Ich bin aber auch der Meinung, dass eine weitere Info via Email auch angebracht gewesen wäre, bei den Kunden welche bereits mit Ihnen im Email Kontakt waren.
Leider machte sich der Ausfall bei meiner Webseite sehr stark bemerkbar. Die Datenbank viel Regelmässig aus und im Shop war daher keine Kundenbestellung mehr möglich oder der Shop war sehr oft überhaupt nicht mehr erreichbar. Dies weit mehr über eine Woche.
Der Support hat sich auf jeden Fall sehr bemüht und versucht zu helfen.
Leider hat mir dies in dieser Situation nichts genützt, da das Zeitfenster viel zu lang war und bis dahin keine Lösung bestand, musste ich zwangsmässig den Hoster wechseln.
Ich hatte in dieser Zeit eine kostenintensive Werbung am Laufen und habe so leider einige Kundschaft verloren oder wütend gemacht.
Ich war bis anhin immer sehr zufrieden mit Cyon und bin auch gerne weiterhin Kunde.
Ich hoffe einfach das in nächster Zeit keine grösseren ausfälle kommen.
Danke für die Kenntnisnahme und Liebe Grüsse
Dominik

Danke für Deine Rückmeldung, Dominik. Das Zeitfenster war in der Tat lang, und auf die oben erwähnte, äusserst schwierige Fehlersuche zurückzuführen. Dass Dich das zu einem Wechsel des Hosting-Partners gezwungen hat, tut uns sehr leid. Wir freuen uns aber, dass Du uns mit anderen Projekten treu bleibst. Die Kommunikation per E-Mail hatten wir grundsätzlich geführt, wieso Du aber nicht mehr weiter informiert wurdest, klären wir ab.
Herzlichen Dank für Dein Verständnis.

Das ganze liest sich wie ein Krimi – und war für das Cyon-Team vermutlich auch einer ;-)
Besten Dank für den Ausführlichen – und sehr lehrreichen – Bericht!

Vielen Dank auch von mir für diesen sehr ausführlichen und interessanten Bericht!
Es ist schlicht NICHT möglich, immer ALLES 100 % unter Kontrolle zu haben. Solche Sachen sind zwar äusserst ärgerlich für alle Beteiligten, aber leider nicht vermeidbar. Gerade dann schätze ich es aber sehr, wenn entsprechend informiert wird, wie das nun geschehen ist.
Gruss

Guten Tag
Vielen Dank für die Ausführliche Beschreibung. Es wäre sicher angebracht einen Link zu dieser Seite an alle zu senden, die euch per Mail auf den Ausfall aufmerksam gemacht haben zumal Sie das auch im Mail versprochen haben.
Was mir fehlt ist die Redundanz in der Systemlandschaft. In der Beschreibung geht nicht hervor, dass cyon über mehrere Umgebungen verfügt, auf der Updates und Patches mit entsprechenden Lasttest getestet werden können.
Es ist mir auch aufgefallen, dass während der Downzeit sogar die cyon Webseite nicht erreichbar war. Sie haben also alle 65’420 Websites mit 37’316 Kunden auf ein Storage gepackt.
Ich kann nur hoffen, dass dem nicht so ist, weil sonst das nächste Disaster vorprogrammiert ist.
Liebe Grüsse
Lorenz
Redundanz gibt es bei uns grundsätzlich reichlich, was aber nicht alleine gegen jede Art von Ausfällen schützen kann. Auch ein Test-Ceph-Cluster ist vorhanden, auf welchem wir alle möglichen Tests machen.